


In the Wikipedia galaxy, my late grandfather Johnny Jacobs, a radio and television announcer well known enough to have a Wiki page but not famous enough for it to qualify as more than a “stub,” used to be born in Texas. Though I never met Johnny, my dad has repeatedly told me he was born in and grew up in Milwaukee. Back at home, we have a picture hanging in the den of Johnny and his grammar school football teammates. In his early adolescence, he apparently had a perpetually broken nose, and this snapshot, with tape over his bridge, is no different. His face evinces a rough, Depression-era Milwaukee upbringing by a single mother. Those eyes have seen things. If you could guess a person’s birthplace from their early teenage stare, Milwaukee, in this case, would make an excellent choice.

The small guy in the middle, with the tape.
Anyway, the record has since been corrected. I have a faint memory of changing his birthplace anonymously on Wikipedia myself, but when I checked this user’s other edits, it indicated that I had also changed Howie Mandel’s page to reflect comments he made to Conan O’Brien about his wife’s vagina. These have since been deleted by other users. I do not recall making such a change, so maybe I wasn’t the one.
Or perhaps I was. After all, in June 2009, I was in college and living at home for the summer. It was around the same time that I was a bussing for a salad restaurant in West Hollywood. I later dropped that job to take a production assistant gig on VH1’s reality television show Sober House with Dr. Drew. Over the course of a month or so of 12-hour days, I hand-delivered Dennis Rodman his Church’s Chicken lunch; drove the late Mike Starr, the original bassist in grunge band Alice in Chains, to Arby’s; and was supposed to stand guard and ensure Tom Sizemore didn’t escape the premises of another not-so-memorable dining establishment. Differentiating absolute fact during this seemingly fictional haze is hard.
Nevertheless, someone with a Los Angeles IP address corrected my grandfather’s birthplace on Wikipedia, so it was probably me.
COUNTLESS OTHER ERRORS ON Wikipedia—probably some on the pages I just linked to—remain unchanged or in a constantly morphing state of sort of-kind of-almost-right. The Wikipedia galaxy is very large indeed, and it must be impossible for its army of unpaid volunteers to successfully search its skies for errant lights, let alone correct the routes of bunk information satellites. Before long, they collide with other space junk and the misinformation cascades into the solar system of someone else’s reality. This is perhaps one reason Wikipedia constantly begs for money (and Bitcoin).
But if experts in Bayesian statistics have it their way, the job of sorting through and rating these heaps of data might get easier down the line. As a pair of professors from Nanjing University in China explain in a new paper which appears in the International Journal of Information Quality, it’s something of a necessity:
First, given the huge size of collaborative content, manual assessment will eventually cease to be feasible. Second, human judgement is subject to bias. To overcome these drawbacks, a possible solution is to design automatic or semi-automatic quality assessment policies.
According to Wikipedia, there are close to 4.6 million English entries currently on the site. Lots of them are terrible. In pursuit of a way to eliminate stray Texas birthplaces, the researchers designed dynamic Bayesian network algorithms that can sort through and rank entries on the basis of their quality. This would allow Wikipedia editors to use more of their time tackling a prioritized list of problem entries, instead of sitting there and making the unending list themselves.
The duo concocted quantitative measures of accuracy (“the extent to which data are correct, reliable and free of error”), completeness (“the extent to which information is not missing and is of sufficient breadth and depth”), consistency (“the extent to which information is present in the same style and compatible with previous data”), and minimality (“the amount of distinct factual information”). Their equations also accounted for the quality of the contributors as well: “administrator (adm), registered contributor (reg), anonymous contributor (ano) and blocked contributor (blo).” Theoretically, the algorithm would spit out corresponding quality ratings: “featured article (FA), good article (GA), B-class (B), C-class (C), start-class (ST) and stub-class (SU),” which are the same ones Wikipedia uses internally. They also used “multivariate Gaussian distributions” (read: other statistics I don’t understand) to ensure they were placed in the correct quality class. But does all this produce realistic quality ratings?
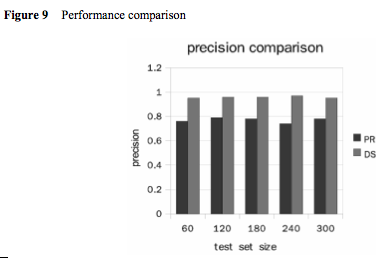
TO TEST OUT THEIR mathematical models, they amassed more than a thousand entries about computing (because, well, they are obviously computer geeks) and went to work. The model was incredibly precise. When it accounted for all four quality dimensions, it hovered around 96 percent precision in predicting the correct rating. Here’s the graph:

The algorithm also out-competed a “state-of-the-art” 2007 model “by a percentage between 17 and 23.” Here’s the comparison:
Once the terrible posts are identified, though, an ungodly amount of work remains. If Wikipedia could ever afford to adopt this sort of algorithmic system, “Jimbo” Wales and his global team of volunteers might not have enough patience or generosity left to evaluate its results.

