


Shortly after the collapse of the Soviet Union, the economist Paul Seabright purportedly sat down with a senior Russian official to discuss moving from a centrally planned economy to something more akin to market-based capitalism. “Please understand that we are keen to move toward a market system,” the lapsed Communist began, the story goes. “But we need to understand the fundamental details of how such a system works. Tell me, for example: Who is in charge of the supply of bread to the population of London?”
To Seabright, the question was, of course, folly. No top-down figure is in charge of the web of individuals who act both independently and in concert to ensure that the denizens of London get their scones and English muffins each day. Further, that bread network is too diffuse and multi-varied to be detailed in a short response. The route of interactions—between farmers, ingredient-sellers, bakers, merchants, bread-eaters, and the like—that ultimately produces London’s bread is difficult to track, and even harder to explain as a coherent snapshot in a quick meeting.
Our lives are largely made up of decentralized hives, systems whose individual parts can be difficult to discern from the whole. Like London’s bread market, the Internet is one such network of many actors. But what, in the most tangible sense, does the Internet actually look like?
As a scholar of Internet topology and professor of computer science at the University of Wisconsin, Paul Barford studies interrelated networks to earn his daily bread. Consequently, he would often get asked a similar question to the Russian’s query: “Can you show me a map of the Internet?”
After years of being unable to satisfactorily respond to this question, Barford set out to provide a visual depiction of the Internet—across the United States and the world. But what should a map of the Internet look like? A scatter-plot of geo-concentrations of posting? Mapped locations of Internet service providers’ headquarters, maybe?
Barford considered many approaches to this question, but ultimately settled on the physical infrastructure that makes possible the dissemination of all this data and content—the roads, guardrails, and jughandles of the proverbial “information superhighway.” Six years, one Department of Homeland Security grant, and a miscellany of tedium later, Barford and his team of researchers created the Internet Atlas, an evolving geospatial map of Internet anatomy that Barford says can both improve our web and make it safer. Pacific Standard spoke with Barford about his recently released Atlas, net neutrality, and more.

What is the Internet Atlas?
It’s a repository of maps of physical Internet infrastructure: the locations of buildings where the hardware that transfers [data] are actually housed, and also the physical conduits—in other words, fiber-optic cable—that connect those buildings together. We built the largest repository of these maps and a Web portal enabling the maps to be accessed, visualized, and analyzed. Most of our effort has focused on the U.S., but we do have network maps for infrastructure over the world.
Why map the “physical Internet infrastructure”?
If we understand the deployment and capabilities of current infrastructure, then we can potentially improve it. We can make it perform better, so your downloads or streaming is higher performing. We can make [the infrastructure] more robust, meaning the chance of having disruptions due to outages or other kinds of events goes down. We can also make it more secure, which means making it more robust to intentional attacks that take place pretty much on a daily basis.

(Photo: University of Wisconsin–Madison)
Additionally, I’ve been studying Internet topology for over 20 years now, and I couldn’t answer a very simple question that people would ask me. They’d say: “So, you study Internet topology. Can you show me a map of the Internet?” And before the Internet atlas, I couldn’t.
How much of that infrastructure is public or shared, and how much is private?
It turns out that almost no infrastructure is public. The cables and buildings that house the devices that transmit data are owned almost exclusively by private entities. At least the aspects that you and I have access to. There are government networks used primarily by the military, but commodity traffic [for public use] isn’t available on those networks. All of the Internet that you use, that I use, is owned by companies, and these companies charge us a monthly fee to get access, or certainly charge businesses fees to be able to use that infrastructure.
And are there redundancies in the infrastructure because of private companies not sharing their infrastructure?
Yeah! There’s actually a tremendous amount of redundancy of the Internet today, and we see evidence of this all the time. [Disruptive] events take place on the Internet all the time, but most of these events end up only having very localized effects—maybe the service on your block, or your building, goes down for some period of time. But that doesn’t have any impact on 99.999 percent of the users on the Internet. Most of the time, service is very reliable, and in the case where events do take place, there is a tremendous amount of redundancy that enables fast bail-over, and for connectivity to be restored very quickly.
So redundancy of Internet infrastructure is good because it allows information to be sent over different routes when chokepoints get clogged?
That’s exactly right. In fact, that notion of redundancy was actually one of the main motivations for starting the Internet in the first place back in the 1960s. The more you grow the web of connections, the better it works.
This project was funded in part by a Department of Homeland Security grant. I understand that different parts of the Web infrastructure are attacked regularly, necessitating continual security upgrades at each point of entry. But how exactly does an aggregative map of those points contribute to national security?
The entirety of the physical Internet infrastructure is not owned by any individual entity, so no individual entity has a perspective on all of the infrastructure. It’s almost never that case that when you access the Web—let’s say you go to Google from some random point in the world—the data that you’re transferring from Google to your host system doesn’t just traverse one network, it probably traverses 10 or 15 networks, depending on where you are. Infrastructure that’s owned by 10 or 15 different people.
Because of the fact that we have this extremely diversified ownership of the Internet, it makes it very difficult to secure. By having it on a map and having an understanding of where and how these pieces of Internet infrastructure connect together, we can understand where vulnerabilities exist and how we might improve the robustness to certain kinds of attacks, or where we might improve certain kinds of infrastructure to gain better performance. We’re taking something that used to be very opaque, and bringing it into focus and then considering different security threats once we have this information.
Could making such a map publicly available make an attack on Internet infrastructure easier, if someone were able to see how everything is connected?
We’re very, very careful about who we actually give access to the repository. We worked very closely with the Homeland Security folks, because we recognize that this can potentially be used for bad purposes. If you want to get access to what we’ve put together, you have to go through an application process through Homeland Security.
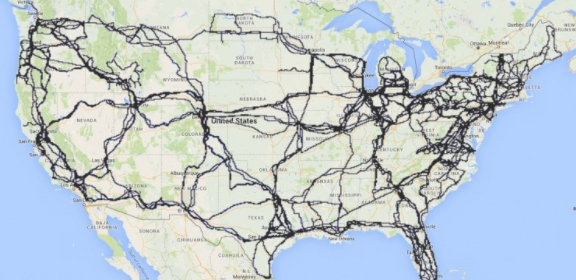
(Map: Paul Barford/University of Wisconsin–Madison)
However, the sources that we’ve used to put this information together are publicly available. So you could actually build your own Internet atlas if you wanted to, but it would take you a tremendous amount of time and effort, even though the data is publicly available. It’s made available by the groups that actually own this infrastructure. If you search something like “Internet maps” or “network maps” or “network maps in the United States” or “AT&T’s network maps,” you’ll find a lot of representation.
It’s been a painstaking process of tens-of-thousands of man hours, over a period of six years, to get to the point where we are. And even though what we have is very large, I would never tell you that it covers the entire globe yet. We still have a lot of work to do. But we are only using public information, that you could access today to put this repository together.
You’ve said that the Internet Atlas should be part of the net neutrality conversation. How are the two related?
What does a “neutral network” actually mean? One aspect is the notion of common carriers. The Communications Act of 1934 stipulated that, if something is declared a common carrier, then the physical assets have to be made available to any entity. Back then it was the phone line, but now it could apply to Internet infrastructure. In the old days, if a single entity owned some telephone lines, they had to make those lines available to any other company that wanted to use them.
And in the net neutrality debate, the same thing is relevant, meaning that, if they move to declare Internet infrastructure as common carriers, then it means that any company can get access to any physical infrastructure. So if we have a neutral Internet, we have a lot of folks who can get access to cables that are already deployed. That means more sharing of infrastructure, and what our findings show is if you have more sharing, then there is potentially more vulnerability.
And so the map would be helpful in understanding our vulnerabilities if common carrier doctrine applies to Internet infrastructure.
Exactly right.
This interview has been edited for length and clarity.


